6、波束形成
波束形成是指將一定幾何結構排列的麥克風陣列的各個麥克風輸出信號,經過處理(如加權、時延、求和等)形成空間指向性的方法,可用于聲源定位和混響消除等。
波束形成主要分為:固定波束形成、自適應波束形成和后置濾波波束形成等。
2語音識別的基本原理
已知一段語音信號,處理成聲學特征向量之后表示為,其中表示一幀數據的特征向量,將可能的文本序列表示為,其中表示一個詞。語音識別的基本出發點就是求,即求出使最大化的文本序列。將通過貝葉斯公式表示為:
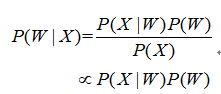
其中,稱之為聲學模型,稱之為語言模型。大多數的研究將聲學模型和語言模型分開處理,并且,不同廠家的語音識別系統主要體現在聲學模型的差異性上面。此外,基于大數據和深度學習的端到端(End-to-End)方法也在不斷發展,它直接計算 ,即將聲學模型和語言模型作為整體處理。本文主要對前者進行介紹。
3聲學模型
聲學模型是將語音信號的觀測特征與句子的語音建模單元聯系起來,即計算。我們通常使用隱馬爾科夫模型(Hidden Markov Model,HMM)解決語音與文本的不定長關系,比如下圖的隱馬爾科夫模型中。
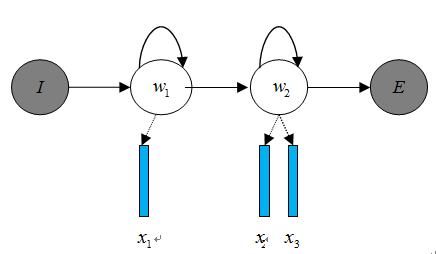
將聲學模型表示為
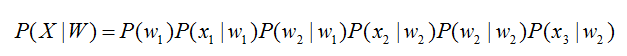
其中,初始狀態概率和狀態轉移概率( 、 )可用通過常規統計的方法計算得出,發射概率( 、 、 )可以通過混合高斯模型GMM或深度神經網絡DNN求解。
傳統的語音識別系統普遍采用基于GMM-HMM的聲學模型,示意圖如下:

其中,表示狀態轉移概率,語音特征表示,通過混合高斯模型GMM建立特征與狀態之間的聯系,從而得到發射概率,并且,不同的狀態對應的混合高斯模型參數不同。
基于GMM-HMM的語音識別只能學習到語音的淺層特征,不能獲取到數據特征間的高階相關性,DNN-HMM利用DNN較強的學習能力,能夠提升識別性能,其聲學模型示意圖如下:
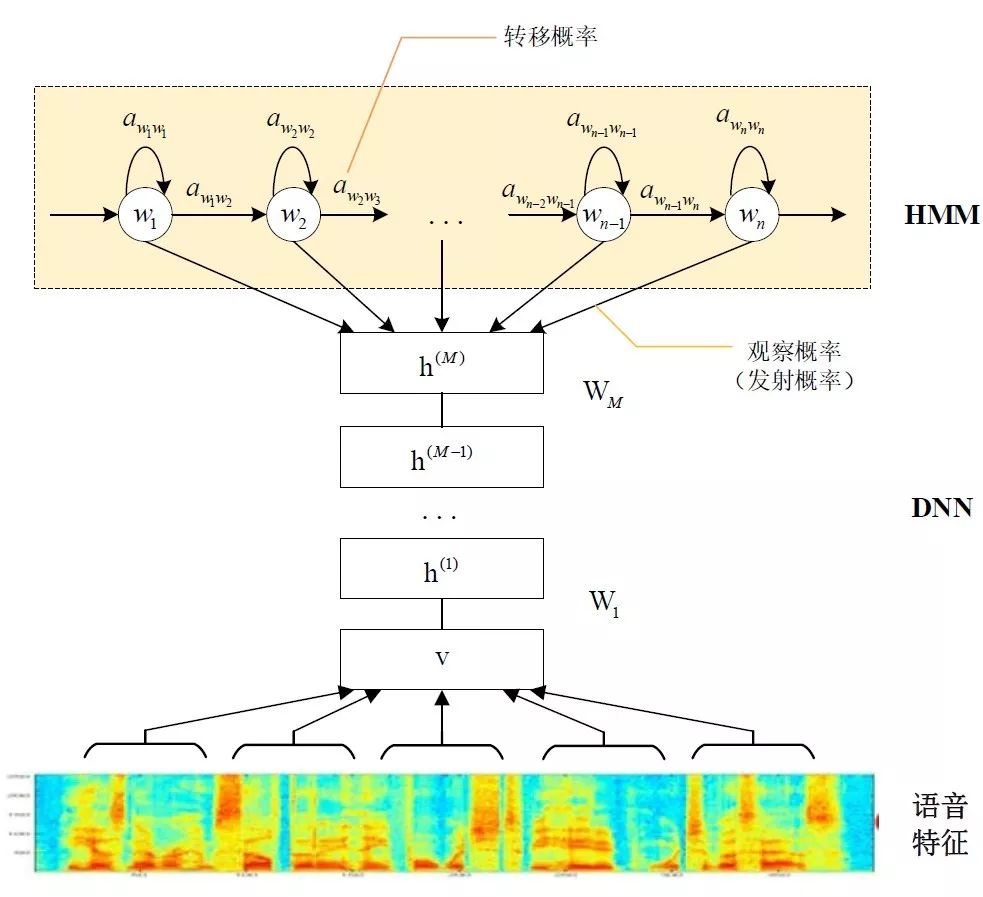
GMM-HMM和DNN-HMM的區別在于用DNN替換GMM來求解發射概率,GMM-HMM模型優勢在于計算量較小且效果不俗。DNN-HMM模型提升了識別率,但對于硬件的計算能力要求較高。因此,模型的選擇可以結合實際的應用調整。
4語言模型
語言模型與文本處理相關,比如我們使用的智能輸入法,當我們輸入“nihao”,輸入法候選詞會出現“你好”而不是“尼毫”,候選詞的排列參照語言模型得分的高低順序。
語音識別中的語言模型也用于處理文字序列,它是結合聲學模型的輸出,給出概率最大的文字序列作為語音識別結果。由于語言模型是表示某一文字序列發生的概率,一般采用鏈式法則表示,如是由組成,則可由條件概率相關公式表示為:

由于條件太長,使得概率的估計變得困難,常見的做法是認為每個詞的概率分布只依賴于前幾個出現的詞語,這樣的語言模型成為n-gram模型。在n-gram模型中,每個詞的概率分布只依賴于前面n-1個詞。例如在trigram(n取值為3)模型,可將上式化簡:

5語音識別效果展示
基于PC的語音識別展示demo如下視頻所示:
視頻包括使用“小致同學”喚醒設備,設備喚醒之后有12秒時間進行語音識別控制,空閑時間超過了12秒將再次休眠。
我們的語音識別算法已經部分移植到了基于AWorks的cortex-m7系列M1052-M16F12 8AWI -T平臺。語音識別的聲學模型和語言模型是我司訓練的用于測試智能家居控制的相關模型demo,在支持65個常用命令詞的離線識別測試中(數量越大識別所需時間越長),使用讀取本地音頻文件的方式進行語音識別“打開空調”所需時間0.46s左右。下面是在M1052-M16F128AWI-T的實測效果:

6關于算法庫獲取
目前語音識別系統處于研發階段,廣大客戶可將自身需求反饋給周立功單片機有限公司與致遠電子有限公司相關市場人員,我們會以最快速度研發客戶需要的產品。

M1052-M16F128AWI-T產品圖片